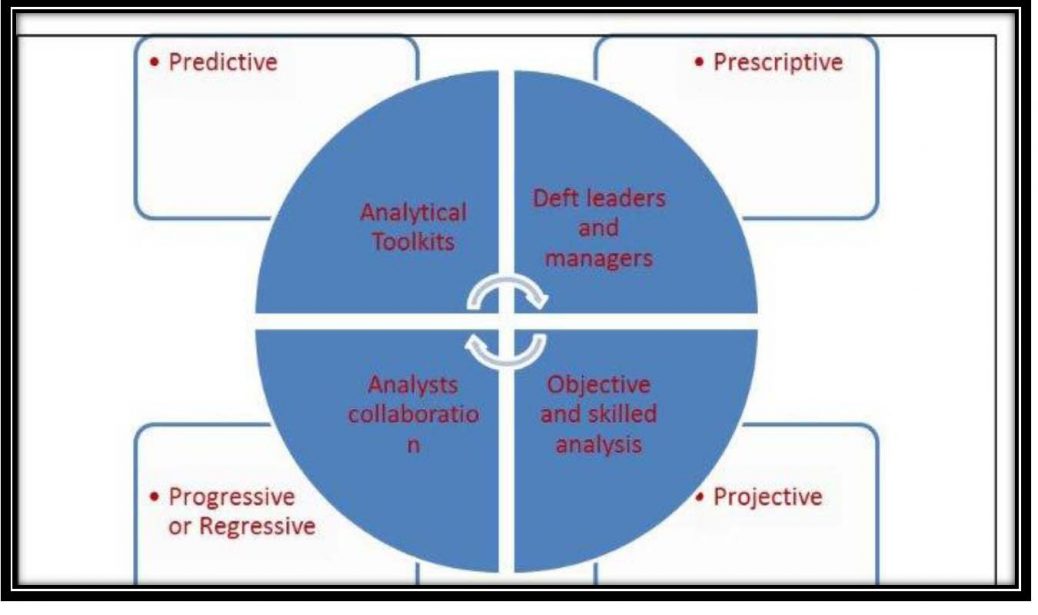
Applying analytic techniques to large data sets, and using predictive modeling have rendered insights into: (a) how the organization’s goals would interact;(b) how optimizing for net revenue would affect turnover, quality of operations, portfolio diversity and other key productivity indicators; as well as (c) how the likely impact of changes would affect the organization’s existing strategies. Subject to reality check or practicality tests, predictive modeling has provided practical and impractical results. The practical ones were implemented while the impractical ones were used to rethink policy decisions (Berg, 2012). From a data leveraging context, modern organizations that counted on consolidated command and control architectures were at a disadvantage because not only were networks dispensing valuable data at every distributed node, but the competing technologies had strengthened the levels of connectivity between humans (scan through here at (Jofdt.com). In addition, anecdotal evidence has alluded to the dangers associated with humans depending on computer algorithms and other forms of data analytics to acquire an enhanced view of the world. Such dangers included the inability to distinguish the level of significance associated with every modicum of data, thus giving meaning to the emerging idiom “dumb learning”. Wisniewski (2013) warned against the uncertainty of modeling because of the feedback loop. In data modeling, the feedback loop can happen if the model were to give the researcher the deception of control; thus likely affecting the data to be a self-fulfilling prophecy. The author concluded “It doesn’t mean the models are right, but they become more right if they’ve engendered trust” (Wisniewski, 2013, ¶ 3). In addition, Wisniewski (2013) warned of the inherent risk embedded in many of the new data models and algorithms; claiming that some of the techniques were biased in favor of predatory marketers (Anonymous, 2012; Wisniewski, 2013).
The goal of pre-purchase preparation was to garner deeper transaction insights to guide the consumer during his or her shopping decisions. Today, pre-purchase preparation at the consumer level has evolved to the use of technologies in cash flow estimation; and other forms of financial modeling to improve information about one’s financial picture. Such technologies were designed to help the consumer avoid making wasteful, needless and unwanted purchases. In addition, institutions were using consumer based predictive spending patterns to provide data nuggets at the point of sale as another channel to deliver more personalized spending information to the consumer. For example, such data products might show the consumer his or her general spending on a Wednesday in comparison to previous Wednesdays. Data products like those on “spend management” guidance have been propagated in the market place because technologies that provide better aggregation capabilities, have increased the velocity in transaction processing and the growing mobile technology market (Wisniewski, 2013). As a mechanism, the value brought forth by modeling could only be as good as the clarity of insights extracted from an organization’s mission, goals and priorities that were compatible with the firm’s culture. Data consistency over time as well as data quality could likewise be important. Using the best models at one’s disposal would only account for a part of the variance to be explained. For instance in econometrics, models have ignored external factors like the unforeseen changes in a market sector’s dynamics, or the pricing and policy changes coming from the competition. So, since predictive models have been based typically on historical data, significant changes to the structure of the current consumer pool will militate against the model’s predictive power (Berg, 2012).
Globally, multinationals have concentrated resources to extract value from the emerging data sources that constitute big data. Notwithstanding, there were significant problems managing big data will have to address. For example, data scientists faced the fundamental flaws in modeling like, tendentious assumptions, the overabundance of new data sources; and data obesity stemming from the indiscriminate hoarding of data. The increasing competition in the contemporary data products industry has lowered the prices in the information retrieval technologies to the point where it is now feasible to analyze data and tender customized data products to meet the need and context of the consumer (Wisniewski, 2013; Greller & Drachsler, 2012). The traditional use of questionnaires and interviews as data gathering instruments has presented substantial barriers in terms of scope, time requirements, cost, and authenticity. Nowadays, competing technologies have lowered the cost of data collection by data-mining the digital footprints; while automating the behavioral analysis of any given population. Such technologies rendered more authentic results than the traditional techniques of population sampling. For example, the power of data mining to reflect the real and continuous behavior of the subject equated more to direct observation than the invasive unswerving methods employed traditionally. As a result, the use of sophisticated data techniques has helped to bridge the gap between the subject’s perception and the subject’s behavior (Savage and Burrows, 2007). In yet another example, using the maximum modularity algorithm to assess online communities, the data showed online communities like twitter were more structured than random networks with the same distribution. Modularity referred to the degree a community was self-contained relative to the rest of the corresponding network. Data analysis revealed the variance of word usage found within a social network correlated to the community structure, and that intra-community similarities arose when group participants limited the choice set of topics during communication. In addition, variations in word usage led to the evolution of strongly typed linguistic patterns to the degree that they carried the signature of the societal structure within social network communities. In general, such applications of data analysis techniques have contributed to phenomena like targeted marketing, crowd-sourced characterization and customizing the online experience of consumers (Braden, Funk & Jansen; 2013).
Anecdotal evidence has supported the view that technologies used to leverage big data have catalyzed the rate of success among participating companies. Such companies have had to hire workers equipped with the skill sets necessary to capitalize on the big data wave. Currently, enterprises have begun to experience the benefits brought forth by the ensuing paradigm shift in thought and analysis. For yet another example, the current understanding and using of real time data within the deep silos of the Internet of Things (#IoT) or the Industrial Internet of Things(#IIoT) remains as a pivotal trajectory toward examining organizational costs and benefits. Historically, companies have applied business intelligence and data warehousing models to structured data successfully. To satisfy the modern consumer, the influx of unstructured, and real-time data from the modern competing technologies like cloud computing, low-cost data storage, and faster networks; has brought about new and different ways of thought and analysis, to manage amorphous data more quickly and proactively (Brynko, 2013). At the resource level, big data companies have been forced to move away from the traditional data architect and data administrator; in favor of the data scientist or data researcher whose skill set allows for more insight in leveraging big data (Brynko, 2013). In the business intelligence (BI) arena, the past and current structures of business intelligence support within organizations have been increasingly becoming ineffective. The explanations for such ineffectiveness include:(a) BI’s focus on technology at the expense of ignoring business outcomes; (b) a dearth of commitment to BI initiatives at the executive level; (c) out-moded project management and IT methodologies applied to BI initiatives; (d) the project-based approach in addressing BI issues; and (d)the focus on the features of utilitarian coverage surrounding BI tools at the expense of making the competent efforts necessary to understand and apply data effectively(Evelson, 2013). For the references used in this article and for continuous reading, please scan through chapter 14 inside here at Jofdt.com







{kind=link}